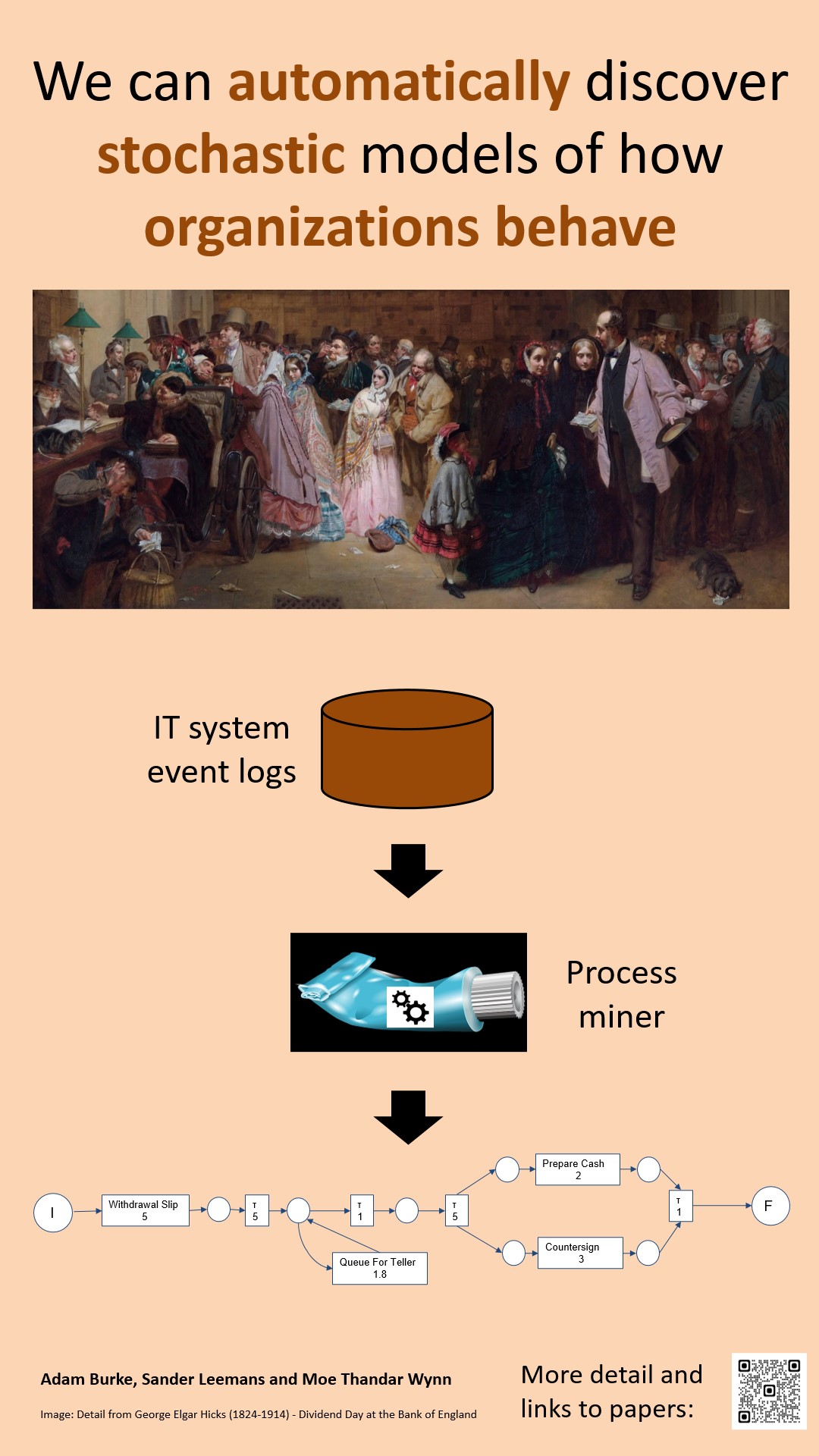
Poster Child For Stochastic Process Discovery
For a number of years now it’s been possible to automatically build models of how organizations behave based on event data from their IT systems. This is called process discovery, and the overall technical discipline for working with these data and models is called process mining.
To date, the success of process mining has mostly been with causal models and diagrams - “this causes that”. With stochastic models, we can also represent rarity, uncertainty, and confidence about given events happening at particular points in a process.
My recent research, with Sander Leemans and Moe Wynn, has introduced two different frameworks for doing stochastic process discovery:
- Toothpaste Miner - a direct discovery technique, where reduction rules summarize a log as a stochastic model [blog post] [paper]
- Stochastic Weight Estimation - techniques for annotating probabilistic weights on control-flow models discovered with existing discovery algorithms. [blog post] [paper]
I will have a poster introducing these discovery techniques at QUT’s Centre of Data Science’s End-of-Year Showcase.
References
Burke, A., Leemans, S. J. J., & Wynn, M. T. (2021). Stochastic Process Discovery by Weight Estimation. In S. Leemans & H. Leopold (Eds.), Process Mining Workshops (pp. 260–272).
Burke, A., Leemans, S. J. J., & Wynn, M. T. (2021). Discovering Stochastic Process Models By Reduction and Abstraction. International conference on applications and theory of Petri nets and concurrency.