State Snapshot Miner and Elite Qing Career Paths
Process mining is really quite a general toolbox for building computational models from sequence data. To date, it’s been applied to sequence data exported from modern IT systems, most often for some form of workflow optimisation or auditing. In our latest paper, we had a great opportunity to use process mining on a quite different type of data. We took information on civil service appointments in the Qing (1641-1911) and built stochastic models of their career paths. The research team included two other process mining researchers, Sander Leemans and Moe Wynn, and quantitative historian and China scholar Cameron Campbell.

The Qing was the last Chinese imperial dynasty, or from another perspective, a large, successful early modern land empire comparable to Romanov Russia. China had a long tradition of recruiting many civil officials through multiple rounds of extremely competitive examinations, which the Qing also employed. A gazette was published four times a year listing every single civil service position, called the jinshenlu. A wonderful project by historians in the Lee-Campbell group has digitised these records and assembled them into the China Government Employee Database - Qing (CGED-Q JSL).
We focused on elite Han officials from 1830-1904, as the data quality of those records was well established. The data posed some interesting challenges. Crucially, elite officials often held simultaneous roles, with different timescales. To describe this data, we exchanged the traditional event log for a state snapshot log, where each entry in a trace could hold multiple roles. To build models from these logs, we introduce a new discovery algorithm, the State Snapshot Miner.
The State Snapshot Miner produces weighted Petri nets where roles are represented by places. This exploits the strength of Petri nets in representing concurrency to capture simultaneous roles. The models for elite officials provide evidence that bureaucratic rules of appointment established canonical pathways, and some non-canonical alternative pathways when things varied from the rules.
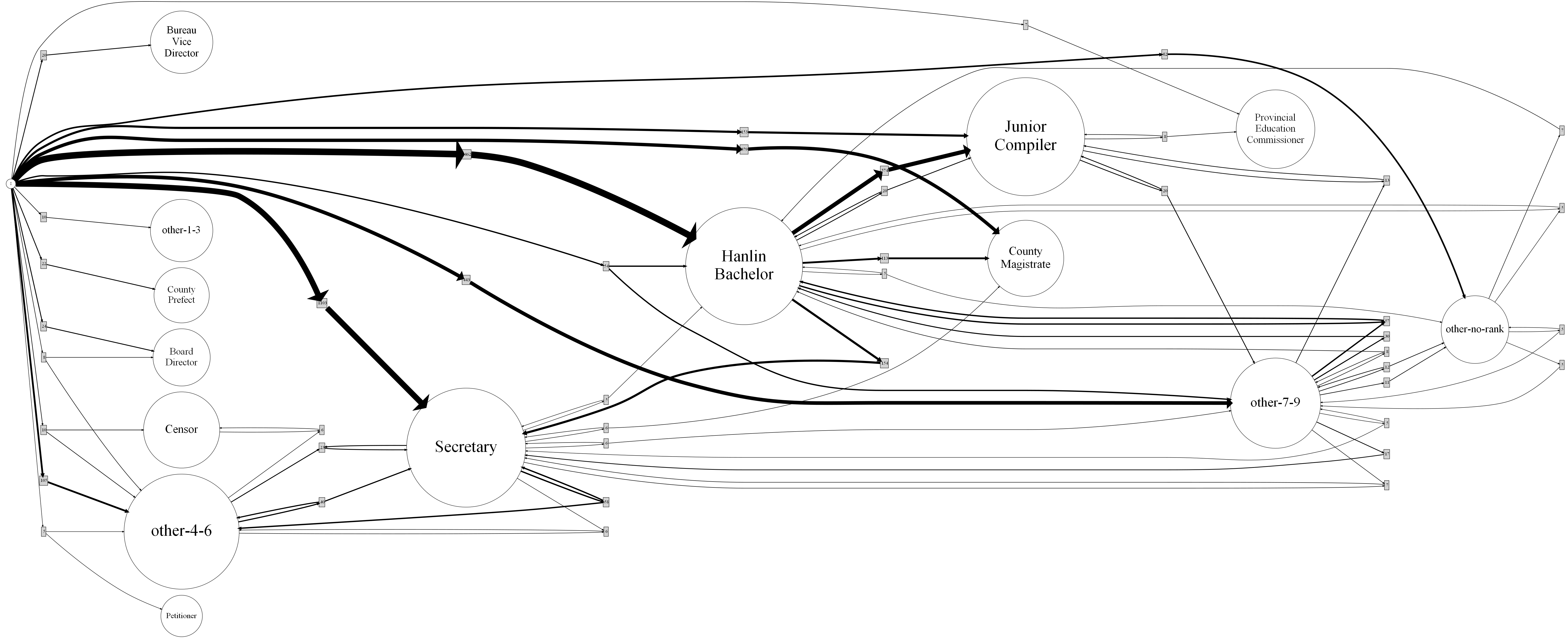
The paper will be presented at ICPM2023 in October. Both a preprint of the paper and a Python implementation of the miner are now publicly available. A sample set of publicly released data is in the github project, and it can be used to generate models using Chinese or English role titles (using a project role dictionary). Cameron Campbell also has a post up on the work over on his research blog.
References
van der Aalst, W. (2016). Process Mining: Data Science in Action (2nd ed.).
Burke, A., Leemans, S.J.J, Wynn, M.T., and Campbell, C.D. (2023). ‘State Snapshot Process Discovery on Career Paths of Qing Dynasty Civil Servants’. Forthcoming at ICPM2023.
Chen, B., Campbell, C.D., Ren, Y. and Lee, J. (2020). ‘Big Data for the Study of Qing Officialdom: The China Government Employee Database-Qing (CGED-Q),’ Journal of Chinese History, vol. 4, no. 2, pp. 431–460, Jul. 2020.